drop_duplicates:去除重复项
|
|
这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行。返回DataFrame格式的数据。
subset : column label or sequence of labels, optional 用来指定特定的列,默认所有列 keep : {‘first’, ‘last’, False}, default ‘first’ 删除重复项并保留第一次出现的项 inplace : boolean, default False 是直接在原来数据上修改还是保留一个副本
Pandas Dataframe增、删、改、查、去重、抽样基本操作
pandas的索引函数主要有三种:
loc 标签索引,行和列的名称
iloc 整型索引(绝对位置索引),绝对意义上的几行几列,起始索引为0
ix 是 iloc 和 loc的合体
at是loc的快捷方式
iat是iloc的快捷方式
https://www.cnblogs.com/zknublx/p/9645204.html
dataframe一列成多列
场景:一列中的值出现 1|2|3|56,这样用|分割的值,需要将其转换成4列。
2、操作:
names=df[‘names’].str.split(‘|’,expand=True)#多名字分列
names.columns=[‘ids0’,’ids1’,’ids2’,’ids3’,’ids4’,’ids5’,’ids6’,’ids7’]#
df=df.join(names)
其中names字段的列是包含|分割的值,最后将多列合并会原dataframe里。
pandas应用函数,它将多个值返回到pandas dataframe中的行
apply 中函数返回一个Series或列表
如返回:pd.Series([e,f,g], index=[‘a’, ‘b’, ‘c’])
https://codeday.me/bug/20180820/223407.html
groupby
1.groupby(“id”).resample(“M”).agg(“mean”)会报错:Exception: Column(s) num_temp selected 并不知道原因
但可以这样
python处理数据的风骚操作pandas 之 groupby&agg
2.这些操作对数值型的列自动进行计算,非数值型的会去掉
如果不对原始数据作限制的话,聚合函数会自动选择数值型数据进行聚合计算。如果不想对年龄计算平均值的话,就需要剔除改变量:
student.drop(“age”).groupby(“id”).mean()
“”统计值””
3.对分组进行迭代:
for name, group in df.groupby(‘key1’):
print (name)
print (group)
python/pandas数据挖掘(十四)-groupby,聚合,分组级运算
Pandas按日期对状态进行汇总统计
《Pandas Cookbook》第10章 时间序列分析1. Python和Pandas日期工具的区别2. 智能切分时间序列3. 只使用适用于DatetimeIndex的方法4. 计算每周的犯罪数5.
详解
时间序列划分时间间隔
在进行数据操作时, 经常会碰到基于同一列进行错位相加减的操作, 即对某一列进行向上或向下平移(shift).
我需要计算网络数据包之间的时间间隔,使用pandas的实现过程如下。
例如 a = [‘2011-08-10 03:56:10’, ‘2011-08-10 03:56:20’, ‘2011-08-10 03:56:40’, ‘2011-08-10 03:56:50’], 时间字符串列表。
import pandas as pd
import numpy as np
将a转换为Series结构, b = pd.Series(a)
将b转换为DateTime数据类型, c = pd.to_datetime(b)
计算时间间隔TimeDelta, d = (c - c.shift()).dropna()
计算间隔了多少秒(将TimeDelta类型数据转换为基于秒的整数), e = d.map(lambda x: x/np.timedelta64(1, ‘s’))
* Pandas计算出的时间间隔数据的类型是np.timedelta64, 不是Python标准库中的timedelta类型,因此没有total_seconds()函数,需要除以np.timedelta64的1秒来计算间隔了多少秒。
也可以将Pandas的Series转换成numpy的ndarray后计算间隔的秒数:
b = np.array(a)
c = np.diff(b)/np.timedelta64(1, ‘s’)
*numpy的diff()函数实在是太赞了。
使用Pandas获得数据的时间间隔序列
python对列进行平移变换(shift)
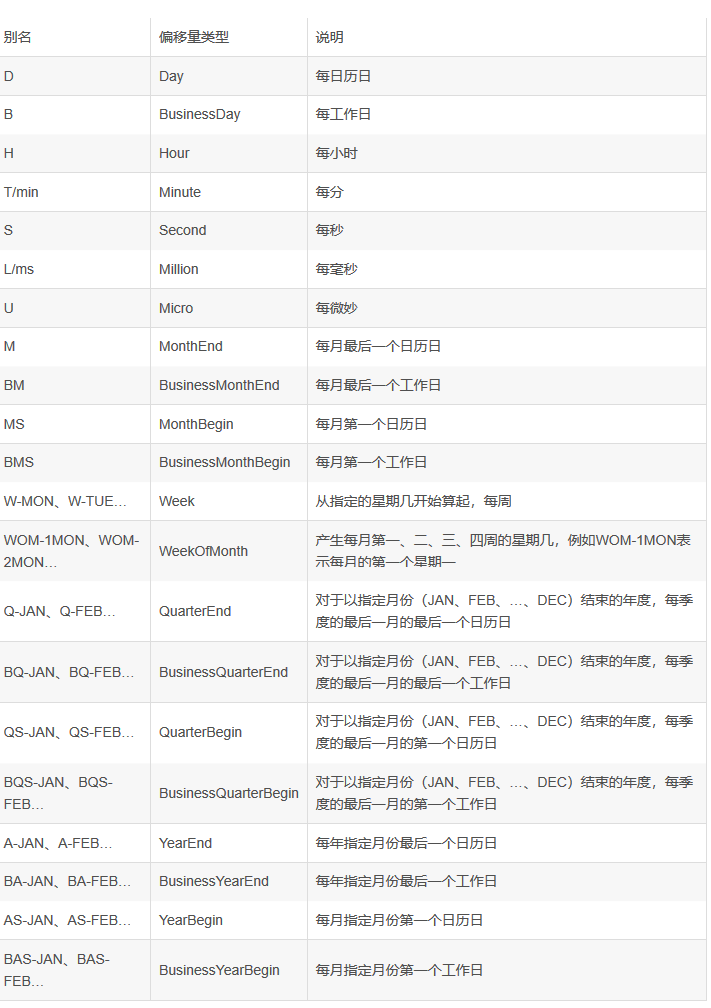
pandas 时间序列 之日期范围、频率及移动中图
!频率选项
##
|
|
滑窗,Rolling 和 Expanding 待研究
移动窗口函数
一种用于时间序列操作的重要用法,是使用滑窗(sliding windown)或呈指数降低的权重(exponentially decaying weights),来对时间序列进行统计值计算和其他一些函数计算。 这个对于消除噪声或有缺陷的数据是很有用的。这里我们称之为Moving Window Functions(移动窗口函数),不过其中也包括了不适用固定长度窗口的函数(functions without a fixed-length window),比如指数加权移动平均数(exponentially weighted moving average)。和其他一些统计函数以后,这些函数也会自动无视缺失值。
作者:蜘蛛侠不会飞
来源:CSDN
原文:https://blog.csdn.net/qq_40587575/article/details/81205873
多级索引
给妹子讲python-S02E16多级索引Pandas的取值、分片与运算
总结
value_counts()
是计数,统计所有非零元素的个数,默认以降序的方式输出Series。
##describe
df.describe()
describe函数总结数据集分布的中心趋势,分散和形状,不包括NaN值


{kind=link}